The Surprising Things That CSS Can Animate / Coder’s Block
— Read on codersblock.com/blog/the-surprising-things-that-css-can-animate/
These are great, the example transitioning the visibility of the modal is especially handy.
The Surprising Things That CSS Can Animate / Coder’s Block
— Read on codersblock.com/blog/the-surprising-things-that-css-can-animate/
These are great, the example transitioning the visibility of the modal is especially handy.
I wanted to note down the zero build step setup I’ve been using for SPA prototypes and hobby projects over the last year. I’ve found this combination of tools and trade offs keeps me productive and gives me peace of mind that I won’t return to a codebase hobbled by abandoned dependencies and breaking changes that often plagues the current Javascript ecosystem.
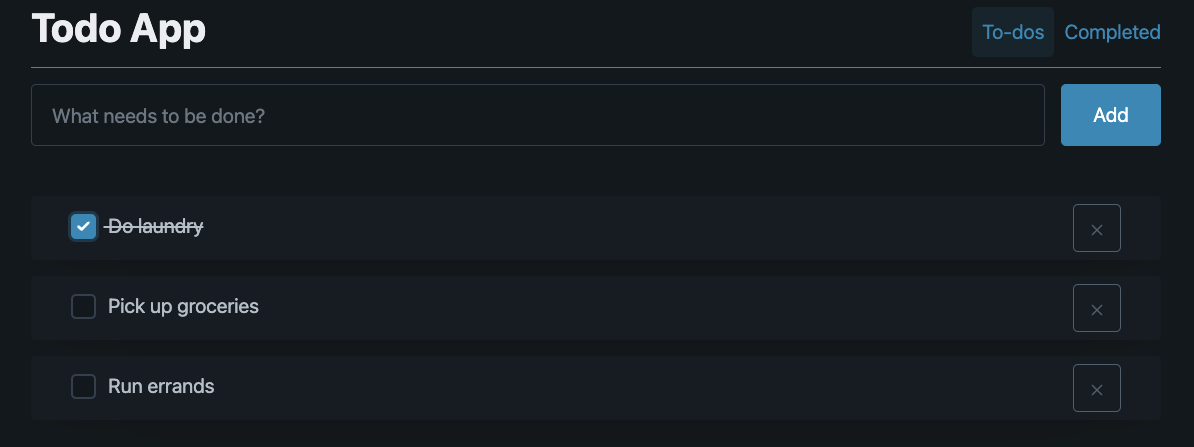
One more todo app for good measure
I couldn’t write about web apps without building another To Do app to add to the heap. Check it out on GitHub: andrewbridge/example-zero-build-webapp
I’ve yet to find another web framework that competes with Vue’s ease of access, and it certainly goes toe to toe with the other big frameworks once you’ve built out fairly complex SPAs. While Vue has considerably outgrown its client side template parsing as a default, I applaud the team’s continued support of this version of the framework.
With Vue loaded, creating an app only requires a few lines of code to get going
import { createApp } from "vue";
const App = {
data: () => ({ message: 'Hello, World!' }),
template: `<h1>{{message}}</h1>`
};
const root = document.getElementById('root');
root.innerHTML = '';
const app = createApp(App);
app.mount(root);From here, plain objects work as components which can be split out into individual files and imported in. See src/index.mjs to see where the To Do app initialises and src/components/TodoList.mjs for an example of a component file.
On top of components, Vue 3 provides a totally independent reactivity API which makes building out your data model very easy. Once you’re ready to reflect your data in UI, Vue components naturally integrate well with this API allowing for fairly complex data flows to be visualised without a tonne of boilerplate.
vue-petite and AlpineJS
In the code sample above, we import createApp directly from a package called vue. Previously this would’ve required a bundler to step in and smooth this over for browsers, but Import Maps now provide us a zero build alternative.
<script type="importmap">
{
"imports": {
"vue": "https://unpkg.com/vue@3.2.37/dist/vue.esm-browser.prod.js",
"goober": "https://unpkg.com/goober@2.1.10/dist/goober.esm.js"
}
}
</script>In our index.html we can list all third party dependencies in one place, providing a name that we can use to import with instead of duplicating URLs.
Support for Import Maps is coming along, but be wary that Safari users or developers will be left out in the cold until the next iteration of macOS and Safari lands. Even worse, this is currently an unofficial specification so could disappear from browsers in the future.
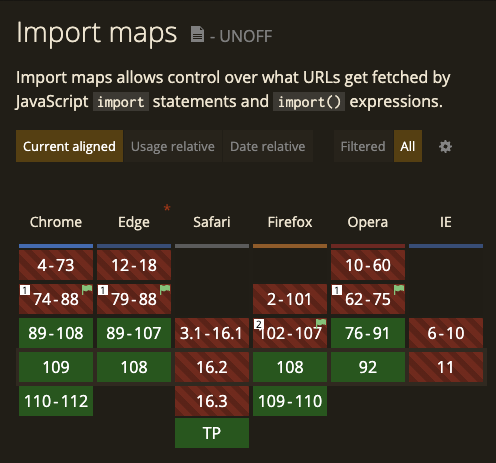
<script> tags will still work, but immediately returns developers to the days of worrying about whether these magic globals will exist at runtime and giving code editors a harder time to keep code safeimport vue from 'http://mycdn.com/path/to/vue.mjs'. You’ll need to be in a script run with type="module" and if you ever need to change the URL, you’ll need to change it in every file that you’ve used the librarydeps directory
deps directory which groups wrapper modules around the import statements for third party libraries. I’ve found a fair amount of success with this technique, especially given the wider browser support, but it does require every item imported from the library to first be imported in the wrapper module before it can be used in the rest of the project.For small projects, a single stylesheets should suffice for the majority of your styles. In fact, most projects where I apply this zero build approach normally use Pico.css or Tabler to do the heavy lifting. But it can’t be denied that scoped CSS can be incredibly useful when you need to make component specific style adjustments.
I’ve settled on goober, a tiny scoped CSS implementation that does away with a lot of the opinions and bulk of the likes of styled-components and Emotion.
What I like most about goober is that I can actually write real CSS (no camelCased CSS-in-JS objects here unless you really want them):
// styles is a string like "go6kj345n" which can be applied to an HTML element's class attribute to apply the styles
const styles = css`
align-items: center;
padding: 8px var(--block-spacing-horizontal);
margin-bottom: 16px;
`;What’s more, goober supports nesting styles and parental effects:
const styles = css`
/* This is a normal style rule */
align-items: center;
/* Nesting: Apply these styles to any element with the "child" class within the element these styles are applied to */
& .child {
font-size: 0.75em;
}
/* Parental effects: Only apply these styles to the element they're applied to if it's a child of an element with the "parent" class */
.parent & {
color: white;
}
`;With everything above in place, we have a working zero-build application with component level styling, reactivity and fuss free dependency management. But what happens to the developer experience once you drop the build?
You won’t get Typescript support at all with this setup. Without a build step to check the typings and strip them away before they hit the browser, you’ll get syntax complaints or complicated, heavy client side parsing getting in the way of productivity.
But JSDoc comments allow us to provide typings into our code while ensuring our code remains valid Javascript.
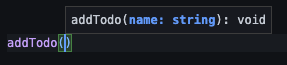
/** @type {(name: string) => void} */
export const addTodo = (name) => {
const id = Date.now();
todos.set(id, { id, name, completed: false });
};
addTodoIf native types aren’t enough, JSDoc comments can also interact with a Typescript types file.
// src/app.d.ts
export interface ToDo {
id: number;
name: string;
completed: boolean;
}
// src/services/data.mjs
/**
* @typedef {import("../app").ToDo} ToDo
*/
/** @type {Map<ToDo['id'], ToDo>} */
export const todos = reactive(new Map());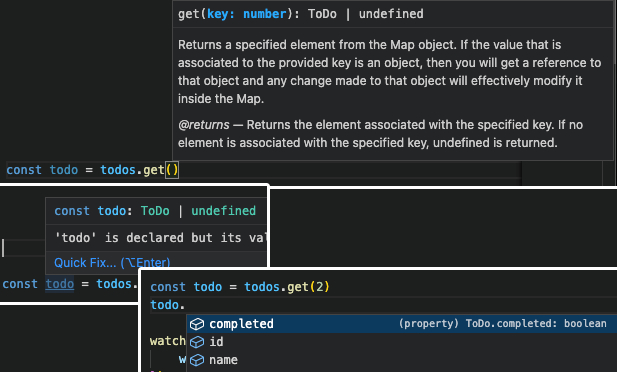
You still aren’t going to get strict type checking and it’s hard to deny that the syntax is more verbose and less natural than what you may be used to in Typescript, but it’s a decent compromise to reach the zero-build goal.
You may’ve been a bit horrified by the amount of markup and CSS shoved into strings when taking this approach. Vue’s object based components use template literal strings for their template argument, while goober is happy to take a string and parse any CSS it can find at runtime.
Here we begin to lean more heavily on the features of your code editor. JetBrains IDEs and VSCode can both be coerced to syntax highlight CSS and markup within template strings, though VSCode will require the es6-string-html extension to be installed. In both cases, you’ll find component markup displays with correct highlighting by prefixing the string with /* html */.
Meanwhile CSS will get automatic highlighting in VSCode because the string is passed to the css method. But JetBrains IDEs will need a little more help.

// language=CSS or // language=SCSS depending on whether or not you’ll be using style nestingI’ve thoroughly enjoyed the simplicity and lightweight nature of a zero-build approach over the last year, but it’s worth bearing in mind this is no replacement for any of the best practices across the web today. Writing SPAs this way:
A Lab-Grown-Meat Startup Gets the FDA’s Stamp of Approval | WIRED UK
— Read on www.wired.co.uk/article/lab-grown-meat-approval
Truly living in the future.
“I Repeat: Do Not Listen to Your Users”
a blog by Jeff Atwood on programming and human factors
— Read on blog.codinghorror.com/i-repeat-do-not-listen-to-your-users/
Interesting to see this article from 2008. A time before people were privacy poor and cookie unaware, the clear message that observing, rather than asking, users to glean insight is the most effective exercise is excellent.
A few months ago I set up my machine for multi-booting (currently set up with 3 OS installs) with the GRUB boot loader running things. I’m taking a guess based on the behaviour here, but this appears to mean:
This shouldn’t cause many issues, as GRUB is widely used and documented, and pretty easy to administer.
However, following this change in my setup, I lost my Wake-On-LAN functionality, a real pain, as one of my installs acts as a Steam box and streams down to my living room.
Based on my assumptions above, I concluded I’d have to set up the Wake On LAN changes in my Linux install to get it working again. For most people, this is a relatively simple process. Have a Google for your specific distro, but the general theme, at least for Debian based distros seems to be the same as detailed on the Kodi wiki. If that works for you – congrats! You’re done.
For me, running sudo ethtool eth0 gave me everything but Wake On LAN information, which was not shown. Both “Supports Wake-on” and “Wake-on” were missing.
At this point, it’s probably best to note a few details of my setup:
3.19.xx (only supported by Canonical now)After a bit of digging, I found that, with my current setup, Linux was using the alx driver for my ethernet card which just happens to be a driver that had Wake-On-LAN support removed due to a bug some were experiencing. Major bummer.
In the linked bug thread above, an auto-installer for a patch to reintroduce this feature was uploaded. Better yet, the same contributor then detailed a step-by-step setup for this auto-installer. Unfortunately, this installer assumes a more up-to-date kernel is in use.
Here’s what I had to change to get things working for me:
$kv variable, set on line 3 caused me issues. A fix is mentioned in later in the bug thread, but for my unsupported kernel, I had to hard code the variable’s value.
$kv variable to clone the linux kernel via git, if your kernel isn’t listed, git won’t be able to continue. Check the wiki page or even the kernel versions available in the git repo to ensure your kernel version is there if you’re getting errors with git.$kv, adding kv='3.18' below line 3 and commenting line 3 out, it being the closest to my kernel version. I am yet to see any negative side-effects, and the installer worked correctlymodinfo -n alx
sudo rmmod alx && sudo insmod {insert the path returned in step 1}
sudo update-initramfs -u
With this all seemingly working successfully, I then rebooted and tested the WOL functionality, which appears to be back again.
Please see the bottom of the page for an update from 2016/08/30.
I’ve been using Cmder for around a year now, and I really like it. It provides me with the goodness of some bash features along with many GNU commands that Linux and Unix users will be familiar with, while fitting in well on top of the Windows Command Prompt. It does this by packaging together several separate pieces of software such as ConEmu, Clink and Msysgit along with a nice looking theme and a lot of scope for customisation.
While you can use a full Bash shell under Cmder, I tend towards the Clink based mix of Bash, familiar commands and command prompt. One issue I’ve found, is that many systems running this configuration will make it hard to run ssh-agent, meaning you have to enter your SSH key passphrase every time you interact with SSH (if you use Git, you probably do this a lot).
Most of the information available online points to using either eval `ssh-agent -s` or eval $(ssh-agent -s). If either of these work for you – great! It certainly works if you go for a full Bash environment. If you don’t have any success, read on.
I want to be able to start an SSH agent in the first terminal I start up, one for each terminal would be inefficient, and a duplication of password entry. Cmder provides you access to a startup script, similar to the .bashrc or .profile files used for Bash. This can be found within the “vendor” folder of Cmder’s program files, the script is a batch script named init.bat.
I’ve added the following to this script (I added it toward the bottom of the script to ensure that the bash command was available):
:: Run ssh-agent initialisation
@if "%SSH_AGENT_PID%"=="" (
@bash D:/cmder/bin/ssh-agent-init.sh
@call ssh-agent-setter.cmd
@del ssh-agent-setter.cmd
ssh-add %USERPROFILE%/.ssh/id_rsa
) else (
@echo SSH Agent already running with PID %SSH_AGENT_PID%
)
vendor/init.bat
#! /bin/bash
eval `ssh-agent -s`
echo "@SET SSH_AGENT_PID="$SSH_AGENT_PID>ssh-agent-setter.cmd
echo "@SET SSH_AUTH_SOCK="$SSH_AUTH_SOCK>>ssh-agent-setter.cmd
bin/ssh-agent-init.sh
The “@” symbol supresses on-screen printing per command, and is used throughout the rest of the script. This code checks to see if the variable SSH_AGENT_PID has been set (one of the two variables which the ssh-agent command attempts to export, and one of the two variables which is required by ssh-add to add your key to the agent). If it hasn’t already been set, the script runs the bash script ssh-agent-init.sh, which I have placed in my “bin/” directory in the Cmder program files, but can be placed anywhere that is accessible to init.bat.
This bash script calls the ssh-agent command under Bash, which works as previously stated, and effectively exports the variables defined by ssh-agent to command prompt and Windows environment variables by generating a batch script with variable setters for each value. Once the bash script exits, the batch script is called and deleted straight after.
Finally, with the required environment variables in place, ssh-add is called, with the default SSH key location specified, though this can be changed or even requested from the user on each start up.
For as long as Cmder remains open, these environment variables will remain defined. Duplicating the terminal in Cmder will also duplicate these environment variables. Duplicated terminals will simply get a message informing the user that an SSH agent is already running, though it may be more desirable to suppress any message entirely in this case.
New SSH agents would be started up if entirely separate terminal tabs are opened, but this didn’t pose a huge problem to me as I usually leave Cmder open and duplicate my current terminal. This script could be tweaked to save the environment variables so long as the ssh-agent was still running (which it wouldn’t across restarts of the machine). I’d also imagine the script could be tweaked to generate the bash script too, thereby not requiring any extraneous scripts, however, it acts as a quick way of calling ssh-agent manually, which is why ssh-agent-init.sh is within the bin folder.
Update 2016/08/30: While the above method does still work, I later discovered that there is a whole command built to get the ssh-agent working correctly already in Cmder. It’s a file called start-ssh-agent.cmd (how appropriate!) and it may already be in your PATH while in Cmder. Try running the command with its full name, if you get an error, it’s probably easiest to search the entire Cmder directory for that file name. Once you find its location, call it in vendor/init.bat instead and everything should work as expected.
Today there have been attention grabbing headlines in a number of news outlets. One of these headlines was “WhatsApp and iMessage could be banned under new surveillance plans”, from the Independent. The article outlined the possibility that technologies and applications, such as WhatsApp, would be banned as they allow users to send messages which are encrypted end-to-end. This falls in line with the new legislation that was rushed through during 2014, and the continuing loss of privacy that we have online.
One quote the article put heavy emphasis on, and in turn has been taken by several other news outlets was as follows:
In our country, do we want to allow a means of communication between people which[…]we cannot read?
My initial urge was to get angry at how patently wrong the connection of encryption and privacy to terrorism and violence was. But then I decided to listen to the full comment from Cameron, rather than the paraphrased version. The full quote is as follows:
In our country, do we want to allow a means of communication between people which, even in extremis with a signed warrant from the home secretary personally, we cannot read?
It’s not much better, but it’s also not as bad as the original quote sounds. The issue is, I can’t say that I want terrorists to be able to plot to carry out these attacks on innocent people, but I don’t believe this is the way of doing it. The fundamental link between not having access to the content of every single communication made anywhere in the UK, and terrorism “winning”, is the key issue. It’s simply a complete fallacy and by allowing the PM to say that unopposed would be us accepting it as truth and allowing the rate of erosion to our online privacy to increase greatly.
Taking everyone’s ability to access a completely private form of communication is a heavy handed tactic which, as I’ve said before regarding government views and ideas on online freedom and privacy, won’t actually work. It is not possible to stop anyone from encrypting communications that they send. It may be possible to stop a company from profiting from offering this type of service, thereby taking it away from the common user, but it is not possible to stop people from doing that.
The types of people that really want communication which is envrypted end-to-end will be able to access it regardless of the law. Included in that user base are those that want to discuss illegal activities. It’s not difficult to find how to set up a method of encryption such as PGP, and the active online community will no doubt offer a great deal of help to anyone that’s stuck.
Further, piracy laws are always a hot topic and probably a good example to learn from. They’re now failing so excessively that the list of “Most pirated shows of the year” is now reported and celebrated. This year Game of Thrones hit the top of the list for a third year in a row after being illegally downloaded at least 8.1 million times. Guess who lost out and weren’t able to enjoy their favourite TV show with everyone else – paying customers in both the UK and the US. Now guess who were able to enjoy it ad-free, only minutes after it finished its first airing in the US – those pirating the episode from around the world.
In the same way, a law stopping completely encrypted, backdoor free communication would simply make the majority of online users more vulnerable to having their personal communications leaked to the public. 2013 and 2014 have been years where, more than ever, it’s clear that we don’t need to increase the likelihood of it happening.
To wrap up my rambling (and procrastination), I will simply conclude that, while I know that giving up our privacy isn’t the right way to help authorities deal with terrorism, I’m not entirely sure what is. I’d imagine that whatever solution is the best will involve far more general knowledge of technology and computer security in UK government. The hackers and cyber criminals of the world are using social engineering, vulnerabilities in code and brute force attacks to get what they want, and it’s working. Maybe trying something that works as well as the criminals’ methods, would be a good place to start.
I haven’t posted here in a long while, and no doubt that will continue unfortunately. However, tonight I’ve learnt (or in some cases re-learnt) a few, albeit simple, lessons and it felt sensible to note it down so I can remember in the future.
This was a massive rookie error and a sign that I haven’t worked in PHP much over the past year.
While tightening my database security, I ended up patching up some dodgy db related code in PHP in a particularly old project. I spent nearly half an hour trying to work out why my passworded database user was being denied access to the database.
After a bit of debugging, I noticed the password was being cut off in the middle, and after further debugging and tracing the string back, I noticed that my randomly generated, double quoted password string happened to have a ‘$’ character in it.
PHP (among other languages) tries to resolve variables within double quoted strings, meaning “abc123$efg456” is resolved to “abc123”, if the variable $efg456 doesn’t exist in your script. The solution was to simply exchange the double quotes for single quotes.
Lesson: If you’re working in a language which treats double and single quoted strings differently, check you’re using the right ones!
.htaccess always ends up leeching away my time. This time I was trying to set up some redirects to treat a sub-directory as the root directoy, but only if the file or directory didn’t exist in the root directory and did exist in the sub-directory.
This is simple enough if you know what the .htaccess variables mean, but in using examples and making assumptions I tripped myself up. So here’s the bit I learnt:
%{REQUEST_FILENAME} – This isn’t just the filename that was requested, but the absolute path from the root of the server.
%{REQUEST_URI} – This is the filename on its own.
%{DOCUMENT_ROOT} – This is usually the path up to the root directory of your site (though I’m quite sure this is not always the case).
So given the path “/a/file/path/to/a/website/index.html”:
%{REQUEST_FILENAME} = /a/file/path/to/a/website/index.html
%{REQUEST_URI} = index.html
%{DOCUMENT_ROOT} = /a/file/path/to/a/website
Simple when you know, but confusing otherwise! In any case, here’s the resulting rule I cobbled together:
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteCond %{DOCUMENT_ROOT}/other%{REQUEST_URI} -f
RewriteRule ^(.*)$ /other/$1 [L,QSA]
That won’t suffice if you need directories to work as expected, and it will only apply to files, but it’s as much as I need for now.
Lesson: Don’t assume things, especially when dealing with something as powerful as .htaccess files. The more you know and use it, the less of a pain it will be.
Having acquired a new domain name today, I decided to put it to work as a domain for my home server (with help from no-ip). Having set it all up, I came across a peculiar scenario where I was able to access the machine remotely with the domain (the outward facing IP), I was able to access the machine locally with the local IP address, but I was unable to access the machine locally with the public IP or domain name.
In a few minutes I realised that this was not so peculiar at all. The Network Address Translation (NAT) rules decide where inbound requests should go when it hits the router, I have my router set up to allow certain connections to forward through to my server. However, these rules don’t apply to requests which pass through the router on the way out. I’d only be guessing, but I’d imagine this is because responses to requests across the Internet would otherwise have these rules applied to them as well, completely breaking the network.
To solve this issue, NAT loopback, a feature or further rule which resolves requests to the router’s public IP from inside the network correctly, is available in many routers. It is commonly turned off due to security concerns, or simply may not be available in some routers.
Unfortunately, my Huawei HG533 router falls into the latter group, with no obvious plans of an upgrade which would fix this.
Lesson: If you want to use one address to access a machine locally and remotely, ensure NAT Loopback is set up.
All simple stuff, but it’s been interesting learning about it all. Hopefully I can continue documenting the small things like this over the next year, my final year of university should be a steep learning curve!
The recent news has featured two main stories, both of which have already been discussed to death. There was the futile efforts at keeping the royal baby news going while Kate had the baby, recovered and walked outside with him in her arms and there was the huge trumpeting of Internet safety from David Cameron. The latter, which the Prime Minister set out as a way of stopping child abuse and guarding children from viewing adult content in one fell swoop, irritated me quite a lot. There were a number of reasons for my irritation…
Mr Cameron also called for some “horrific” internet search terms to be “blacklisted”, meaning they would automatically bring up no results on websites such as Google or Bing.
This calling for search companies to provide a blacklist is actually popular with a lot of people, with the idea that “if you can’t Google it, it won’t be there”. The problems with this method are pretty easy to see, while its effect is pretty minimal:
The “accidentally stumbling” scenario which is often painted out is also well guarded against nowadays, with further, definite steps being required to access content which is deemed inappropriate for some audiences. That is already provided for, many companies do in fact have whole departments devoted to ridding their services of this type of content, or at least flagging it as such to the user.
He told the BBC he expected a “row” with service providers who, he said in his speech, were “not doing enough to take responsibility” despite having a “moral duty” to do so.
The blame was also passed on to ISPs because they weren’t doing enough, with Mr Cameron insisting that they filter the Internet service which they provide. This is where many who care about freedom and worry about censorship begin to get panicky because:
On speaking to my family about this point, it was quickly mentioned that “It’s just like any other law, you wouldn’t complain about not being allowed to drink and drive”. Immediately this argument is flawed, because I still have the ability of having a few too many beers and walking out to my car and driving it, there isn’t a breathalyzer test which I must take before driving, or a guard which won’t allow me to get behind the wheel when I’m over the limit – I still have the ability to commit the crime.
To make this point worse, after the announcement from the Prime Minister, many ISPs came out and described the parental tools which are already supplied by their service, and alluded to the fact that David Cameron’s jubilance, was simply taking credit for work that had already been done.
For the record, I’m actually all for parental controls at the service level, it provides a service wide coverage for the filtering of websites, which means most children will be unable to get past the filters (as most mobile networks impose filters, as do all schools and colleges), especially if the filtering includes proxy servers and websites. However, it certainly doesn’t stop anyone who is over 18 from removing the filters and accessing illegal content online. The idea is to also provide the filters automatically, passing over the parents heads and assuming their computer illiteracy, which leads me on to…
Most parents are probably quite concerned at the thought of their child being exposed to adult content online. Many will actually ensure that a child’s Internet use is supervised at an early age, and any filtering which the parents should be applying to their Internet connection is not absent through choice. Technology companies and the government (as they’re so interested) should be working with parents, providing support, training and user-friendly tools to parents, rather than just applying a blanket filter to all their account holders and patronising them. Clearly this is happening to some extent already, but the level of involvement could certainly do with raising.
As much as many people protest, the parents do have a huge responsibility when they allow their children to use the Internet, just as they do in not allowing them to watch films with an age rating which is too old for them or watch TV channels which are specifically intended for adults. They should be provided with the necessary information to fulfil this responsibility, but otherwise it should be up to them.
The other point that has annoyed many people is the fact that much of the mainstream media now has strong sexual, violent or addiction promoting themes, which have been entirely overlooked in this review.
Examples aren’t possible to count, but obvious examples can be found in most tabloid newspapers, gossip magazines and adverts (that’s printed, televised or digital). These slightly softer images are just as damaging as those more extreme images on the Internet, because they are in publications or media channels which contain everyday information alongside them, normalising them and sending similarly bad messages to children. If the Internet is going to be filtered, the filters already in place in other forms of media should be reviewed as well.
The final, and most concerning thing, is that the government seem to be aiming their efforts at the wrong end of the whole issue.
They do not produce illegal material, nor do they promote it. Asking them to do something about that material is already too far along the line, because by then the illegal act has occurred, been filmed or in some way documented, uploaded publically and then is accessible to anyone that knows where and how to get the content.
It’s like those weed killer adverts, the competitor product always just kills the weed at the surface, not at the root – the material can easily be hidden from view, but that doesn’t stop the root cause.
What really needs to be done is further investigation, more of a focus on finding those that cause harm to others for personal gain, unfortunately Mr Cameron’s budget cuts are actually doing the complete opposite – that’s what makes me quite so irritated.
The whole issue is huge, and calls into question the privacy of Internet users and the freedom of the Internet itself, as well as the degree to which the government are misguided when the word “technology” is mentioned. What David Cameron has suggested will detriment normal Internet users, bastardise the Internet and completely fail to achieve most of the aims which he has set out.</rant>
A stub is a short article which rounds up little bits of information that I’ve found throughout the week. These may be web or computer related, or they may be more general things. It’s more a personal log than an actual article, reminding me of things that I may’ve forgotten, but some of it may be of help to someone else!
Looks like I’ve falled behind with my posts! The year is certainly starting to become busy! So I’d better catch up on the past two weeks!
This er…fortnight:




